Hilf mit, den
Musterdatenkatalog
zu erweitern!
Mit deiner Hilfe können wir den Musterdatenkatalog für Open Data in Kommunen verbessern.
Dein Input verbessert das Maschinenmodell.
WIE FUNKTIONIERT ES?
Dein Input für das Modell
In zwei Schritten zum Musterdatensatz
In zwei Schritten zum Musterdatensatz
Deine Aufgabe ist es, Datensätze aus deutschen Open-Data-Portalen Musterdatensätzen zuzuordnen. Dies passiert in zwei Schritten: zuerst bekommst Du einen Vorschlag für ein Thema, dann eine zugehörige Bezeichnung.
-
Musterdatensatz
Ein Musterdatensatz setzt sich aus Thema und Bezeichnung zusammen.
-
Thema
Das Thema ist eine erste grobe Einordnung und mit einer Kategorie vergleichbar. Da es aber im DCAT-AP Standard nur 13 Kategorien gibt, haben wir diese erweitert. Du hast 62 Themen zur Auswahl.
-
Bezeichnung
Die Bezeichnung ist mit dem Titel eines Datensatzes vergleichbar, nur allgemeiner. Sie ist eine präzise Einordnung eines Datensatzes unterhalb eines Themas.

01
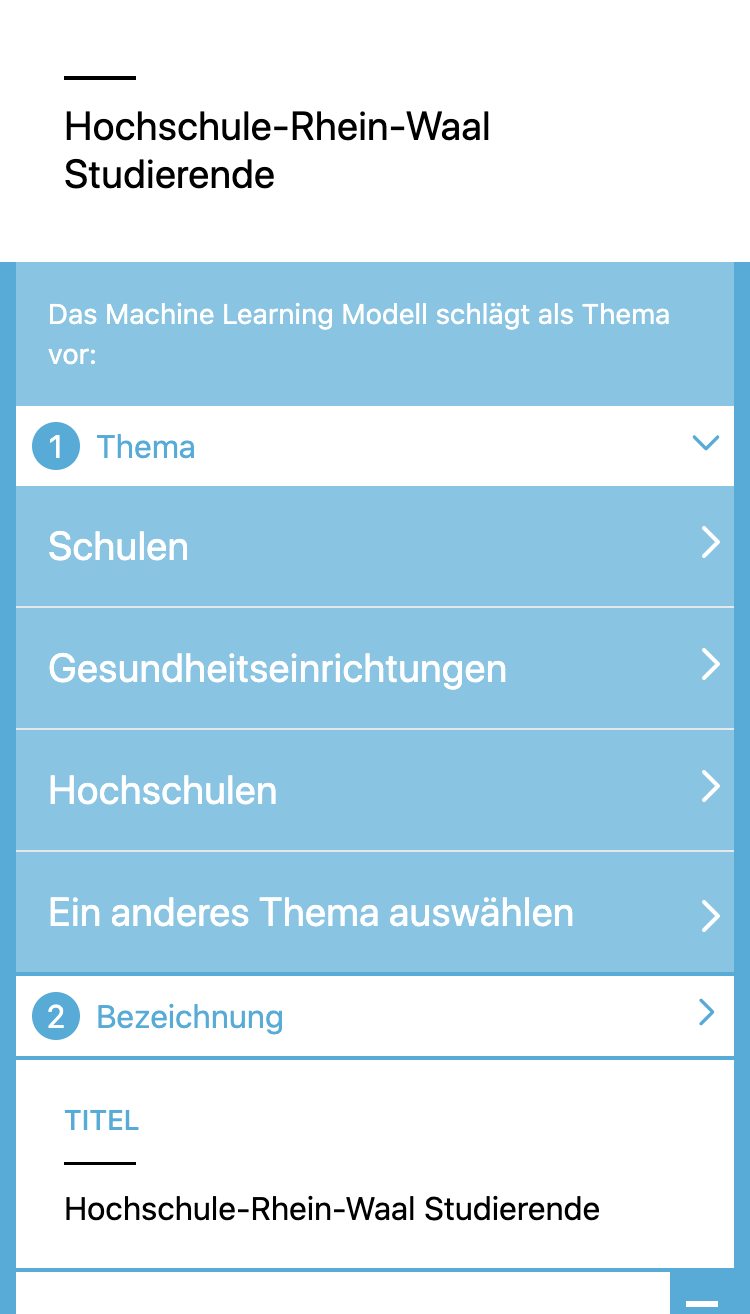
Thema – Du wählst das Thema
01
Thema – Du wählst das Thema
Unser Machine Learning (ML) Modell läuft und macht Dir zunächst einen oder mehrere Vorschläge für ein Thema und anschließend für eine Bezeichnung. Daraus bildet sich der Musterdatensatz. Du kannst einen der Vorschläge auswählen oder aus allen Themen wählen.
-
Auswählen
Wenn Du ein Thema auswählst, geht es weiter und Du bekommst einen Vorschlag für eine Bezeichnung.
-
Ein anderes Thema auswählen
Wenn Du aus den vorgeschlagenen Themen keines passend findest, kannst du selber aus allen Themen eines auswählen.
-
Tipp
Es kann bei der Zuordnung hilfreich sein, parallel den Musterdatenkatalog unter musterdatenkatalog.de zu öffnen. Dort kannst Du bei Bedarf nachschauen, welche Datensätze bisher den einzelnen Themen oder Bezeichnungen zugeordnet wurden.
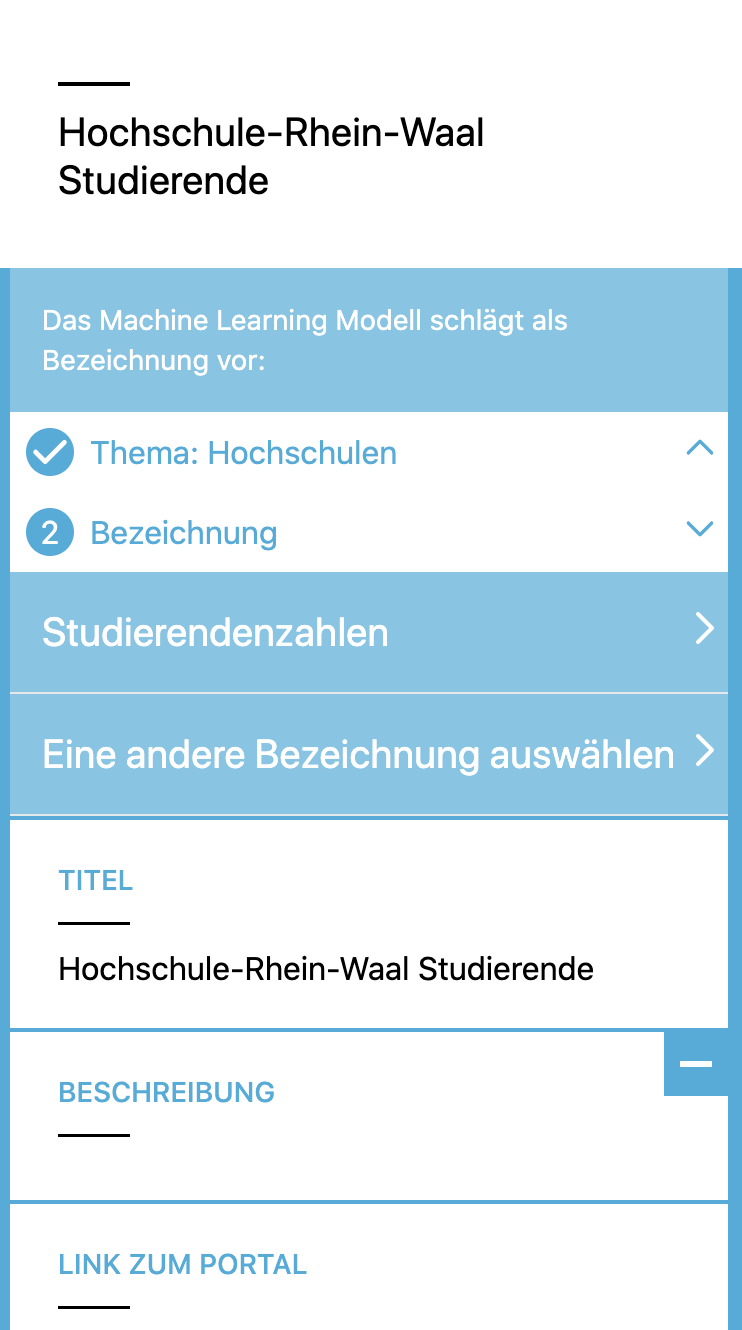
02
Bezeichnung – Passt sie zum Thema?
02
Bezeichnung – Passt sie zum Thema?
Das ML-Modell hat auch eine oder mehrere Bezeichnungen ermittelt. Du hast wieder die Wahl. Nimmst du einen der Vorschläge an, oder wählst aus allen Bezeichnung des Themas.
-
Auswählen
Wenn Du eine Bezeichnung auswählst, bist Du fertig mit diesem Datensatz. Du bekommst einen neuen Datensatz und fängst von vorne an.
-
Eine andere Bezeichnung wählen
Wenn Du den Vorschlägen nicht zustimmst, bekommst Du alle Bezeichnungen des Themas aufgelistet und kannst eine auswählen. Nach der Auswahl bist Du fertig und fängst wieder von vorne an mit einem neuen Datensatz.